Design motivation
Most data manipulation is currently performed using either spreadsheets or data analysis programming toolkits like R or Python. Part of the motivation for my new tool, Columnal, was seeing data analysts struggle with the two – wanting to create more advanced spreadsheets than the software easily supported, but struggling when trying to implement the same analysis using text-based-programming. Below are what I think are some of the shortcomings of the existing solutions and how they can be overcome.
The drawbacks of spreadsheets
Spreadsheets are incredibly flexible and approachable for beginners, but they can get frustrating for processing data sets because:
- It's easy to apply a formula to the wrong cell range (or forget to update existing ranges when you add cells), because conceptually you have a data table, but the software does not have "table" as a core part of its design. Have you ever discovered a SUM() calculation that is out of date because of new rows you added?
- Some more advanced operations are very difficult in spreadsheets. For example: joining two tables by a common column, filtering rows, sorting are either difficult or involve destructive updates. Have you ever sorted a table then later, when it is too late, wanted to "unsort" it?
- Spreadsheets are sparse in their features when viewed as programming interfaces. Modern programming tools have features like rich auto-complete, refactorings, quick-fixes, but spreadsheets tend not to to provide many of these. Have you ever been told there is a syntax mistake in your formula but been given no guidance on fixing it?
- Spreadsheets are a little too flexible. There are many cases of spreadsheets mangling gene names unexpected into a different type, and other issues caused by implicit conversion. Have you ever had a spreadsheet think that a number is a date, or vice versa?
The drawbacks of text programming
Text-based programming is incredibly flexible in its capabilities, and is very powerful. However, it can be quite unapproachable for those who are unfamiliar with it or who only need it occasionally because:
- Text-based programming relies on a lot of memorisation. You need to know the syntax – and without good autocomplete, also the names of all the packages and functions within those packages. This creates a barrier to entry and makes it frustrating to program intermittently. Have you ever needed to write a script but had to start by googling for all the code fragments you need?
- To explore the data, many programming environments encourage running scripts by writing each new line in a live session. But this can make it hard to recreate the analysis and to track where each variable came from. Have you ever found the value that you want, and then had to search through your command history to try to recreate the chain of computations that produced the result?
- Text programming systems often contain a lot of interconnected parts. Installing and maintaining a working installation of a programming language including all the libraries and environment variables can be painful, and this multiples when you have to make sure that multiple people working on a project all have the same set of versions.
My solution: Columnal
My core idea is to retain the approachability and user interface of spreadsheets while reining in their flexibility to prevent common mistakes and add the power that is usually reserved for text-based programming.
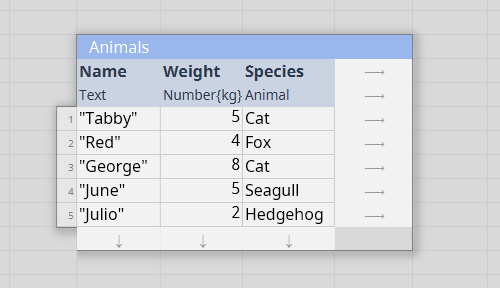
In Columnal, cells are grouped into tables. Tables can have multiple columns, but each column must be the same length and each column must have a consistent type. This immediately makes the design less flexible than spreadsheets, but it gives several advantages relative to spreadsheets, such as:
- It's easy to apply whole-table transformations, such as sorting a table or filtering its rows. In spreadsheets it's really hard to do this without destroying the original table.
- Producing a calculation for each row automatically extends to all rows (without risking missing one) and the formula does not need to be copied and pasted. Updating only involves updating one location, without having to copy and paste the changed formula again.
- Being able to constrain a column's type avoids problems such as a date accidentally appearing in a numeric column, or a 2 in a column meant to be full of booleans.
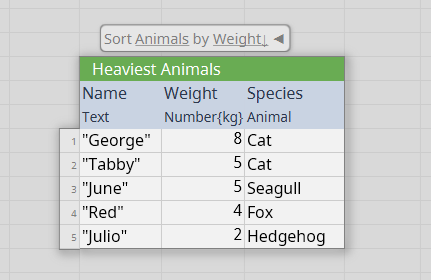
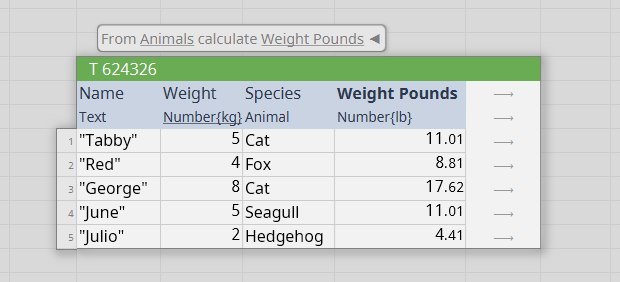
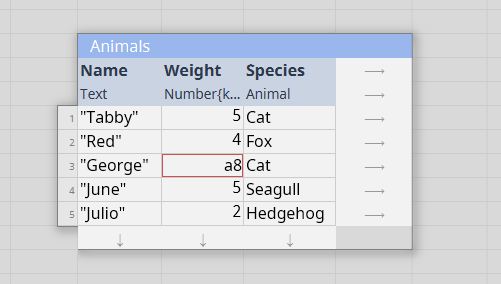
Columnal has many more capabilities but these are a few key features enabled by the table-centric view. Columnal projects are a collection of data tables and transformations. The transformations remember their source and are always up-to-date so there is no need to worry about re-running analysis or tracking how a particular table was calculated.
In future posts I will dive further into the individual features of Columnal and how its design enables its core principle of avoiding mistakes while providing a lot of powerful operations to the user.